Sampling strategies for high quality time-series of climatic variables in forest resource assessment
iForest - Biogeosciences and Forestry, Volume 10, Issue 4, Pages 739-745 (2017)
doi: https://doi.org/10.3832/ifor2427-010
Published: Aug 01, 2017 - Copyright © 2017 SISEF
Research Articles
Abstract
Many ecological studies require long-term time series of high quality. Missing data may represent a serious problem since they can affect the reliability of measured variables in specific locations. To which extent and according to which methodology a gap in time series should be filled is a major research challenge. In this study, the time-series of meteorological data relative to 13 monitoring sites from the ICP-Forest network in Italy were analysed with the aim to define the minimum number of site-specific observations, which can be considered adequate for further analysis on forest resource management. Three main climatic variables were taken into account in the analysis: air temperature, relative humidity and total precipitation. By using an increasing proportion of available data, descriptive and inferential statistic methods were applied to evaluate the amount of variability along the period of analysis (1998-2013) and associated error of estimation at seasonal level. The relative importance of each factor accounted in our analysis (season, year, variable, plot, sampling proportion) was investigated fitting a Random Forest model on the results of the bootstrapping procedure. Air temperature was the variable with a marked seasonal profile and the easiest to be represented at monthly level on a specific time period. Humidity and precipitation were more stable across the analysed time period. Trends in precipitation showed that a high amount of variability could be detected only when > 80% of valid observations were available. Humidity showed an intermediate pattern, with an exponential increase in the amount of explained variability when using an increased proportion of sampled observations. Random Forest Regression models indicated sampling proportion (i.e., number of available observations) as an important factor for trend analysis of relative air humidity and precipitation. We conclude that monthly or seasonal statistics can be proficiently estimated for both air temperature and relative humidity with a proportion of missing values higher than 50%. Conversely, a reliable analysis of intra-seasonal or intra-monthly precipitation variability requires a much higher amount of observations. In the latter case gap filling represents the only feasible solution.
Keywords
ICP-Forests, Sampling Representativeness, Missing Data, Forest Monitoring, Climate
Introduction
A periodic evaluation of meteorological parameters in forest sites can have a central role for the quantification of forest response to the climate condition and to balance future management guidelines and forestry ([35], [8]). In the recent decades the climatological aspect gained an increasing attention also in the forestry field due to direct effects on forest resources ([23], [31], [12], [22]), which in turn are fundamental to preserve ecosystem services biodiversity and multi-functionality by means of a sustainable forest management ([9], [18], [28]). Minimum requirements for ecological studies are generally long-term time series of meteorological variables collected in the environment under investigation or at least in forest sites as close as possible to the studied environment. For this purpose, many meteorological networks have been implemented in connection with research activities and are currently maintained by public programs. The institutional commitment implies that the higher the density of a meteorological network is, the more financial efforts in term of man and operational costs are required to ensure an adequate consistency of the data. ICP-Forests monitoring network was established in 1985 under the Convention on Long-range Trans-boundary Air Pollution (CLRTAP) of the United Nations Economic Commission for Europe (UNECE) with the intent of monitoring climate change effects and human-related pressure on forest ecosystems.
A robust quality check to ensure the absence of missing periods and storage errors is always mandatory and several statistical techniques have been adopted to fill gaps in climatic data series ([11], [14], [36]). Such methods depend more on the availability of data rather than complexity. In case of interpolation of climatic surfaces, a key role is played by the representativeness of the meteorological network often masked by a regular spatial coverage that does not take into account all the physiographic features of a given spatial extent, which play a major role in climate variability ([5], [20]).
Thanks to the diffusion of web knowledge and data storage, many climatic datasets are freely available, generally provided as global datasets with, in many cases, a spatial grid of approximately 1 km cell. Even assuming that statistical downscaling and interpolations are correct for a given site of interest, the representativeness of the obtained dataset requires careful evaluation. To achieve this goal, linear regression methods were adopted, comparing trends of interpolated data with the real data collected in situ ([2], [19]). Such simple methods consider the amount of explained variance and the p-value of the slope parameter as diagnostic indexes of representativeness.
In this paper, the meteorological time-series data relative to 13 monitoring sites in Italy has been analysed with the aim of defining the minimum number of valid data to be considered representative and adequate for further analysis. Three climatic parameters (air temperature, air humidity and precipitation) were extracted from the Italian ICP-Forests meteorological network collected between 1998 and 2013. Then, an increasing number of records were progressively removed using a bootstrap repetition, following evaluation of the representativeness of the remained records in terms of error of estimation and explained variance on the whole climatic period.
Material and methods
The climatic data studied in this research were collected in a 16-year period (1998-2013) from the Italian monitoring network represented by 13 test sites around the whole country (Fig. 1). This network was designed in the framework of the ICP-Forests monitoring program, which probably represents one of the most important sources of information for forest researchers at European level ([1]). As many other European Countries, ICP-Forests monitoring network in Italy is structured in two levels of detail. The extensive network (LEVEL I) is much more represented and was established in 1985 with 243 plots units across the whole forested area of Italy. The intensive network (LEVEL II) is more recent, designed in 1995 under the “National Integrated Programme for Forest Ecosystems Monitoring” (CONECOFOR) with a non-probabilistic scheme and implemented between 1999 and 2003. LEVEL II sites are designed to collect intensive and long-term forestry-related characteristics, such as local meteorology, deposition, crown condition, foliar chemistry, wood increment, carbon storage. The most representative sites selected are Holm oak forests, flood-plain forests, Norway spruce stands, beech and European larch forests ([4], [21]). All the structural forest types (i.e., high forests, stored coppices, transitory crops) are well preserved mature stands in line with the ICP-Forests purpose, which is to investigate climate change and human impacts on forests.
Fig. 1 - Geographic distribution of the ICP-Forests plots. The plots included in this study are marked with an asterisk.
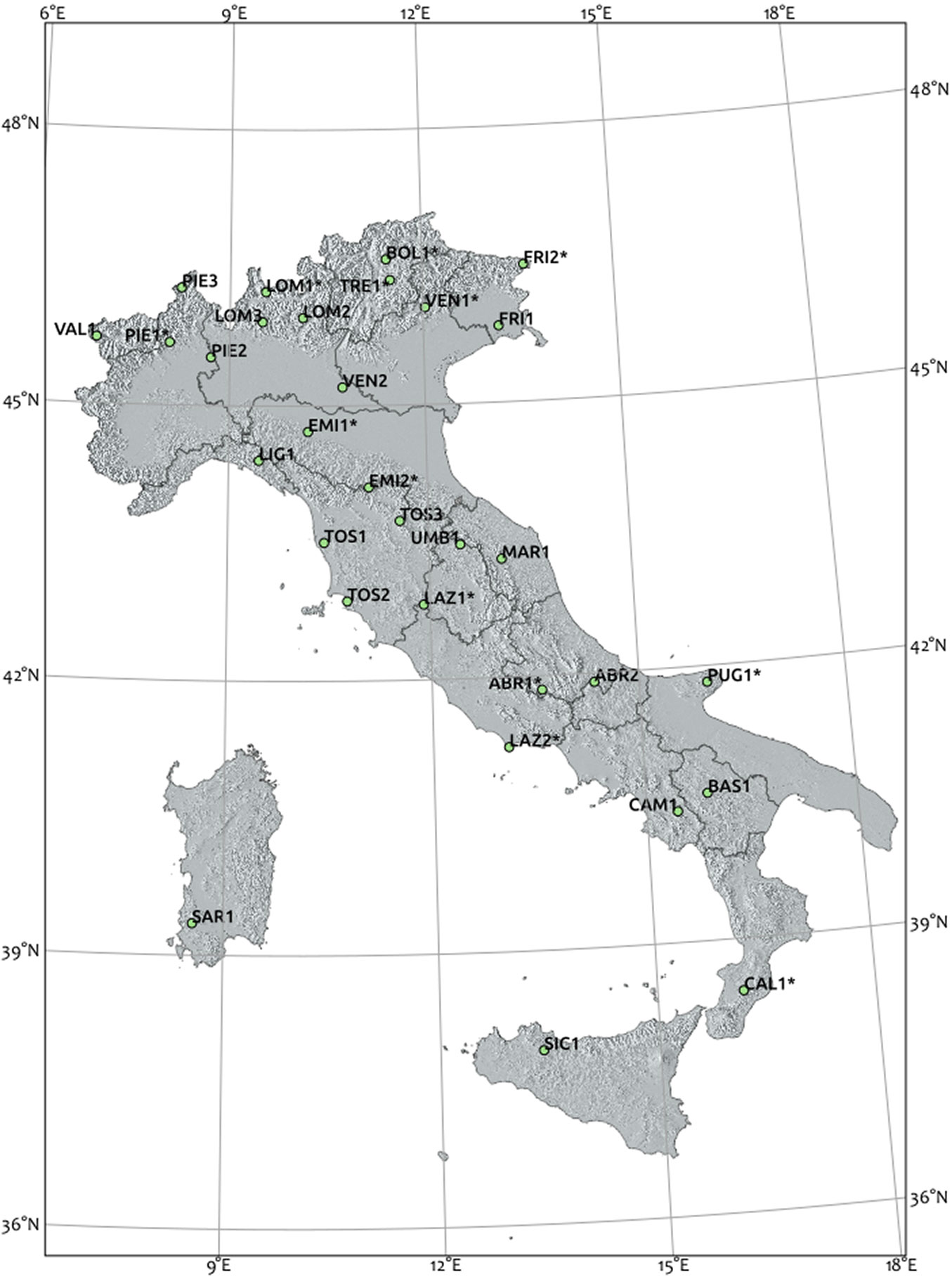
One of the main features of the ICP-Forests network is the availability of local meteorological data, with a meteorological station located in each ICP-Forest plot. The ICP-Forests meteorological network in Italy, one of the most climatically-heterogeneous countries in Europe, revealed mean annual temperature ranging between -0.9 °C and 15.1 °C, and total annual precipitation comprised between 595 mm and 1528 mm. The detected variables, monitored continuously at 10 second time resolution are air temperature for the profile of 0.1 m and 2 m (AT01 and AT2), relative humidity for the profile of 0.1 m and 2 m (RH01 and RH2), precipitation (PR) and snow height (SH). Each meteorological station is equipped with power unit and data logger. Climatic variables are stored in a database aggregated to a temporal resolution of 1 day. All the measurements were conducted below the canopy and the main features of each location are reported in Tab. 1.
Tab. 1 - Selected climatic variables in the study area. (Tmean): mean temperature; (Tdiff): temperature difference; (Py): annual precipitation; (Ps): summer precipitation; (DD5): degree days > 5 °C; (HCMD): Hargreaves climatic moisture deficit.
| ICP-Forests plot | Tmean (°C) |
Tdiff (°C) |
Py (mm) |
Ps (mm) |
DD5 | HCMD |
|---|---|---|---|---|---|---|
| ABR1 | 7.7 | 17.6 | 765 | 280 | 1661 | 195 |
| BOL1 | 3.9 | 17.2 | 999 | 555 | 967 | 0 |
| CAL1 | 12.4 | 16.0 | 952 | 184 | 2819 | 336 |
| EMI1 | 12.5 | 21.8 | 715 | 274 | 3053 | 317 |
| EMI2 | 9.3 | 18.5 | 1376 | 428 | 2063 | 95 |
| FRI2 | 7.6 | 19.4 | 1457 | 688 | 1783 | 0 |
| LAZ1 | 12.2 | 18.3 | 649 | 245 | 2801 | 315 |
| LAZ2 | 15.1 | 14.9 | 821 | 176 | 3787 | 421 |
| LOM1 | -0.9 | 15.1 | 1470 | 800 | 257 | 0 |
| PIE1 | 7.4 | 17.7 | 1528 | 733 | 1629 | 0 |
| PUG1 | 11.9 | 17.4 | 595 | 211 | 2687 | 268 |
| TRE1 | 4.1 | 17.0 | 915 | 534 | 1001 | 0 |
| VEN1 | 12.1 | 21.2 | 1421 | 649 | 2946 | 34 |
In this work, the time lapse between 1th January 1998 and 31th December 2013 has been analysed with 1-day sampling interval for a total of 5844 records. As a first step, we determined the proportion of missing data over the entire time series for each meteorological station, considering AT2 and RH2 representative of AT01 and RH01, respectively (Tab. 2).
Tab. 2 - Characteristics of the climatic time series between January 1998 and December 2013. (AT01, AT2): air temperature at 0.1 m and 2 m, respectively; (RH01, RH2): relative humidity at 0.1 m and 2 m, respectively; (PR): precipitation.
| ICP-Forests plot | Data | AT01 | AT2 | RH01 | RH2 | PR |
|---|---|---|---|---|---|---|
| ABR1 | Valid (%) | 20.8 | 76.5 | 16.8 | 0.0 | 71.5 |
| Missing (%) | 79.2 | 23.5 | 83.2 | 100.0 | 28.5 | |
| BOL1 | Valid (%) | 0.0 | 45.5 | 0.0 | 0.0 | 47.9 |
| Missing (%) | 100.0 | 54.5 | 100.0 | 100.0 | 52.1 | |
| CAL1 | Valid (%) | 51.3 | 50.5 | 51.3 | 0.0 | 51.2 |
| Missing (%) | 48.7 | 49.5 | 48.7 | 100.0 | 48.8 | |
| EMI1 | Valid (%) | 97.5 | 97.5 | 97.9 | 0.0 | 97.9 |
| Missing (%) | 2.5 | 2.5 | 2.1 | 100.0 | 2.1 | |
| EMI2 | Valid (%) | 54.3 | 54.8 | 48.6 | 0.0 | 52.7 |
| Missing (%) | 45.7 | 45.2 | 51.4 | 100.0 | 47.3 | |
| FRI2 | Valid (%) | 82.2 | 82.2 | 82.2 | 0.0 | 78.0 |
| Missing (%) | 17.8 | 17.8 | 17.8 | 100.0 | 22.0 | |
| LAZ1 | Valid (%) | 94.7 | 94.6 | 94.7 | 0.0 | 95.3 |
| Missing (%) | 5.3 | 5.4 | 5.3 | 100.0 | 4.7 | |
| LAZ2 | Valid (%) | 0.0 | 42.1 | 0.0 | 42.0 | 42.0 |
| Missing (%) | 100.0 | 57.9 | 100.0 | 58.0 | 58.0 | |
| LOM1 | Valid (%) | 0.0 | 40.8 | 0.0 | 40.8 | 40.8 |
| Missing (%) | 100.0 | 59.2 | 100.0 | 59.2 | 59.2 | |
| PIE1 | Valid (%) | 70.7 | 70.7 | 70.7 | 70.7 | 70.7 |
| Missing (%) | 29.3 | 29.3 | 29.3 | 29.3 | 29.3 | |
| PUG1 | Valid (%) | 0.0 | 27.5 | 0.0 | 27.5 | 27.5 |
| Missing (%) | 100.0 | 72.5 | 100.0 | 72.5 | 72.5 | |
| TRE1 | Valid (%) | 89.1 | 89.1 | 89.1 | 89.1 | 89.1 |
| Missing (%) | 10.9 | 10.9 | 10.9 | 10.9 | 10.9 | |
| VEN1 | Valid (%) | 82.1 | 85.2 | 82.3 | 84.1 | 84.1 |
| Missing (%) | 17.9 | 14.8 | 17.7 | 15.9 | 15.9 |
Two methods of statistical analysis were performed to obtain estimators aiming at (1) evaluating the error of estimation at seasonal level using an increasing proportion of available data using the Mean Absolute Relative Error (MARE); and (2) evaluating the amount of explained variance (r2) along the whole analysed period (1998-2013) estimating the monthly mean value with the same procedure. The MARE was calculated as (eqn. 1):
where {hat}γ and γ represent the estimated and the observed seasonal value of AT2 or RH2 or PR, respectively. For each proportion of sampling from 1% to 99% with an increase step of +1% (i.e., 98 repetitions in total) a unique value of MARE per each climatic variable was calculated. In order to avoid biases, a bootstrap procedure was implemented by repeating a random extraction of seasonal values. For each sampling proportion between 1% and 99%, 10.000 random extractions were computed. Then, the final MARE was obtained by averaging the 10.000 repetitions. To facilitate our evaluation, daily records were grouped in triplets of months (season I: January-March; season II: April-June; season III; July-September; season IV: October-December). Concerning the second analysis, we adopted a linear regression approach. A linear model was fitted using the estimated monthly average values (γ’) as independent variable and the observed values (γ) as dependent value. Then the amount of explained variance (r2 of the fitted model) was calculated as follows (eqn. 2):
where {hat}γ is the predicted value of the linear model. Finally, all the results (MARE and r2 for each intensity of sampling) were modelled using the a Random Forest (RF) regression model ([6]) to assess the influence of each variable (i.e., moth, season, year, climatic variable, sampling proportion) and with the purpose of understanding the most relevant drivers. The importance of each predictive variable was estimated from permuting Out-Of-Bag (OOB) data by recording, for each tree, the prediction error (Mean Square Error) on the OOB portion of the data. Then, the same procedure was adopted after permuting each predictor variable. The difference between the two values were then averaged over all trees, and normalized by the standard deviation of the differences ([14]). All the statistical analysis and the RF were implemented in R software ([24]).
Results
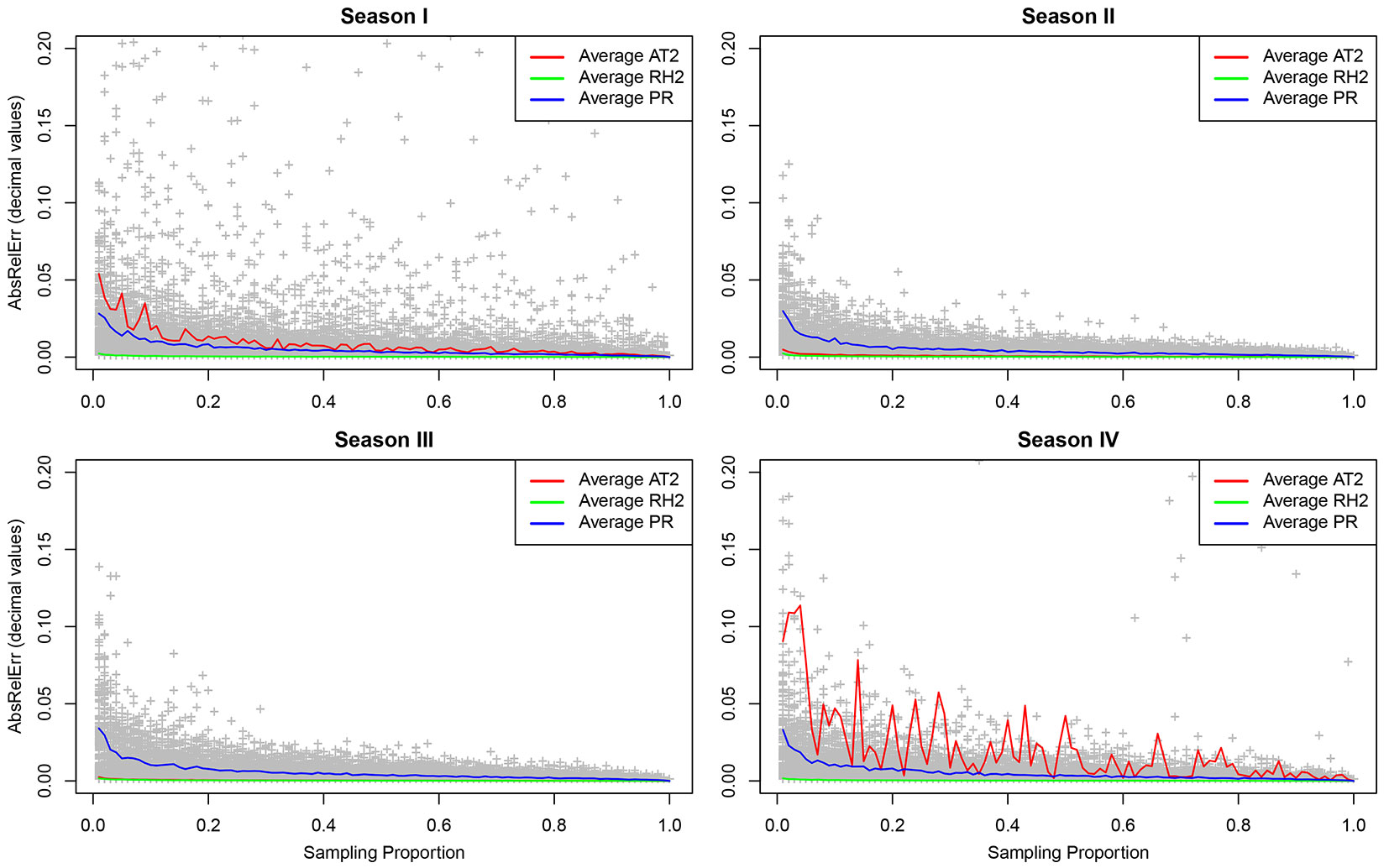
Fig. 2 clearly shows the MARE of AT2, RH2 and PR plotted against the sampling proportion used to estimate the seasonal mean. While for season II and season III an almost uniform and small MARE was calculated across all the sites (plots), a much different result was obtained for season I and season IV. For these seasons, the bootstrap procedure for AT2 resulted in a MARE around 500% with a sampling proportion of 60% of the total seasonal days. Particularly for season IV, an almost flat line for RH2 and PR was observed against a very unstable AT2. We conclude that among the three variables tested in this study, AT2 showed the statistically lowest seasonal accuracy, although this could be due to the presence of outliers.
Fig. 2 - Relationship between the MARE and the increasing proportion of days sampled with the seasonal analysis for the three studied variables
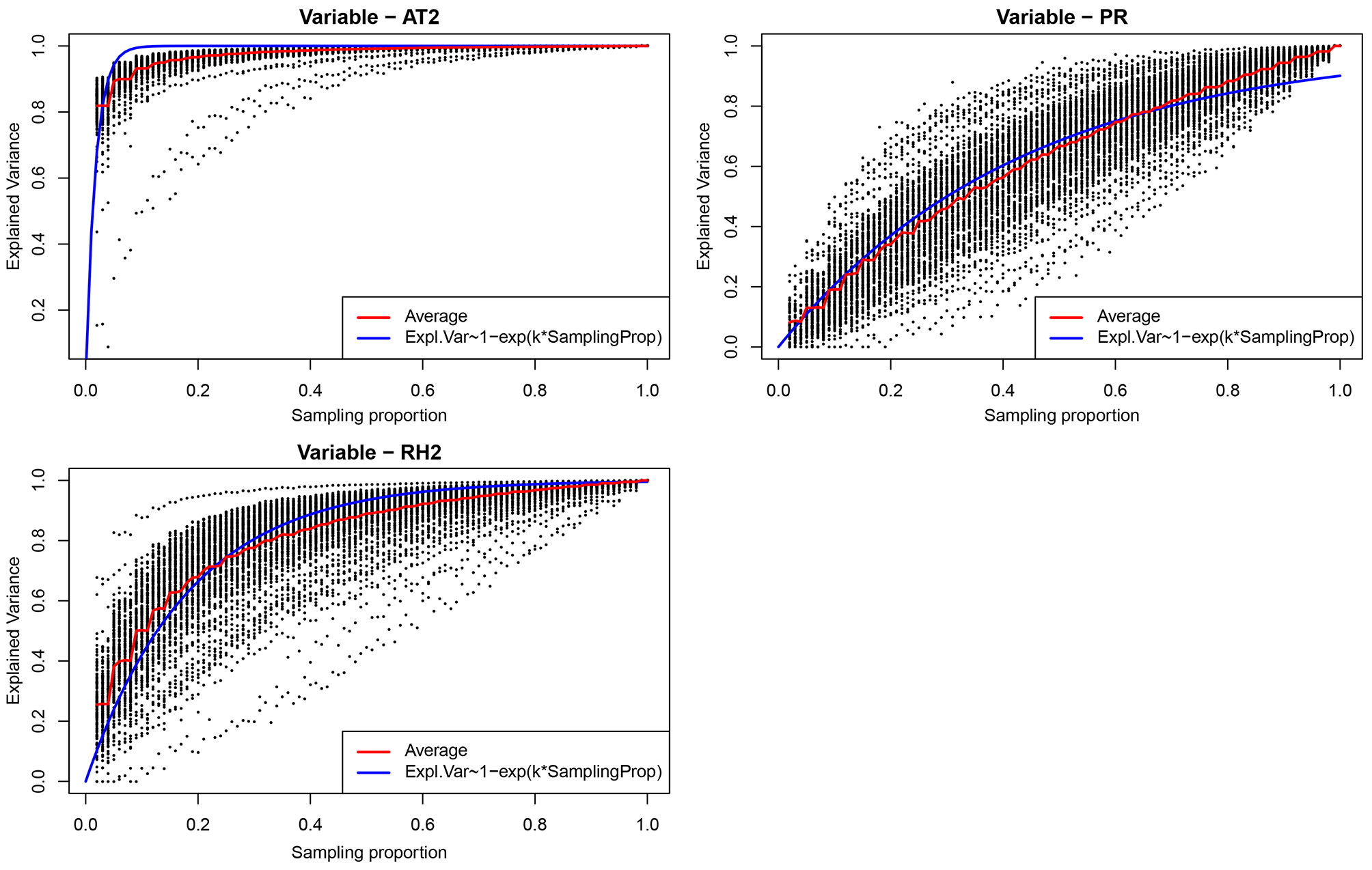
Regarding the representativeness across the whole time period, different results were obtained for each variable. Results for the three variables are reported in Fig. 3 where observations are fitted using a negative exponential model, showing an r2 of 0.98, 0.94 and 0.93 when fitting AT2, RH2 and PR, respectively. The relationship with the sampling proportion showed that AT2 was the variable with the highest amount of explained variance (higher than 85%) with a sampling intensity of 10%. Conversely, PR showed a much more regular trend with an almost linear shape. RH2 revealed an exponential increase until reaching 50% of the sampling proportion.
Fig. 3 - Amount of climatic variability explained when an increasing proportion of monthly values (days) is sampled in the considered climatic period (1998-2013). The red line and the blue line correspond to the average value and the fitted exponential model.
The Random Forest algorithm (RF) was run on the obtained result. In a first test the MARE was modelled as a combination of all the covariates. In the second test the amount of explained variance was modelled without the “season” term. The importance of each predictor is reported in Tab. 3. In the seasonal analysis the sampling proportion (i.e., number of available observations) was found to be a less important variable compared to the others, which were well balanced and not significantly different between each other, with a RF covering 62% of the total variability. On the other side, the RF run on the results of the trend analysis showed that sampling proportion and the studied climatic variable were the most relevant predictors, much more important than the meteorological station and the year, with an amount of explained variance of 92.3%.
Tab. 3 - Variables importance (% increment of MSE) when used as predictors in a Random Forest regression model. (n/i): not included.
| Predictor | Seasonal analysis |
Trend analysis |
|---|---|---|
| Sampling Proportion | 27.5 | 1267.8 |
| Station | 69.3 | 257.7 |
| Variable | 66.1 | 1366.4 |
| Year | 67.3 | 195.1 |
| Season | 72.5 | n/i |
| Var. Explained by the model (%) | 62.1 | 92.3 |
Discussion
In a changing environment, stable and reliable climatic data represent a fundamental resource to investigate the adaptability of forest systems. Many environmental and modelling studies are focused on long-term climatic averages (e.g., climatic normal over a 30 years period) to determine the effects of climate change on forest populations ([15], [22]). However, an increasing degree of representativeness is needed in studies that require a higher temporal-resolution, such as dendrochronology ([2], [19]), or studies based on seasonal effects on plant growth ([26], [29], [16]). The more detailed the analysis is, the more accurate and continuous the database should be. In such cases, missing data and outliers have to be identified and treated before further analysis in order to avoid possible biases. The presence of missing values in a dataset can heavily affect any kind of analysis ([30]), bringing to false expectations or underestimation of natural processes. To improve such datasets at regional level, the statistical downscaling with laps-rate regressions ([25], [13], [27]) or the use of statistical methods such as the Singular Values Decomposition ([7], [33]) may represent the only alternative to the interpolation of local climatic data from monitoring networks. When long time series are needed, data collected from web portals such as the CRU database (⇒ https://crudata.uea.ac.uk/cru/data/hrg/), custom queries using stand-alone software ([34]) or object-oriented web portals (e.g., ⇒ http://climexp.knmi.nl) may represent the only solution. Our findings clearly highlight that, in case of monthly or seasonal average values, very few records can still allow accurate analysis of climate trends. Especially in the case of PR and RH2, a very small MARE was detected with a limited amount of measurements (<10%). AT2 showed a much wider difference between seasons, although we ascribe this to the presence of outliers, especially at ABR1 and FRI2 where the mean value of monthly air temperature is close to zero. In particular, while a similar standard deviation was found for almost all the plots in the same months, in FRI2 the coefficient of variation of AT2 was much higher than any other meteorological station. As a consequence, the high MARE in AT2 was mainly due to the small mean values in season I and IV, where most of the months are characterized by a low mean temperature. Results suggested that more attention on data collection should be paid during cold seasons given that almost all the meteorological stations experienced high air temperature values at least during the season II and III across almost the whole Italy. Under future climate changes a fundamental role will be played by extreme events, recognized as a high peak or depression after and before an almost stable climatic situation. Actually extreme events have been demonstrated to have a fundamental role for forest systems and plants communities even in Mediterranean areas ([10], [17], [3], [32]) and such rare and unpredictable events will require even more accurate and gap-free time-series to understand the effects of these events on forest ecosystems.
Although trend analysis showed that AT2 was the most seasonal-dependent variable, a low amount of data is required for its monthly representativeness. On the contrary, the trend analysis showed that PR requires consistent database (> 80% of valid data) to avoid relevant biases. RH2 showed an intermediate behaviour between AT2 and PR with an exponential increase of the amount of explained variability with an increased proportion of sampled days. This may be explained by the intrinsic temporal autocorrelation of such climatic parameters. Indeed, air temperature values are much more autocorrelated than relative humidity and precipitation.
In conclusion, our results may play a fundamental role both in case of local analysis (forest type - local climate) but also for the purpose of site comparison. Indeed, many efforts were spent to homogenize climate time-series for different sites by means of spatial interpolation with the use of external climate data ([36]), which expose to the risk of adopting unrealistic values. We demonstrated instead that when minimum requirements are accomplished (i.e., number of records per unit of time), the use of external databases may be avoided. This, of course, still implies that a rigorous data check for outliers should be performed. When monthly or seasonal accuracy is required for trend analysis, a high proportion of missing values can be accepted in case of AT2 and RH2, but not for PR due to the intra-seasonal or intra-monthly variability of the latter parameter. Although not the object of this study, when a higher resolution is required (daily or weekly) gap filling such as Singular Value Decomposition or external interpolated data may represent the only feasible solution.
Conclusions
Time series represent the time-evolution of the meteorological dynamic process and are fundamental to evaluate patterns and responses of forest species to climate changes. Accounting for forest response to climate is functional to sustainable forest management. When monthly or seasonal average values are needed, our results indicate that statistics can be proficiently estimated for both air temperature and relative humidity with a proportion of missing values higher than 50%. Conversely, the intra-seasonal or intra-monthly variability of precipitation requires a higher density of observations. In this case gap filling may represent the only possibility to avoid relevant biases. New emerging technologies have the potential to increase the robustness of the dataset thanks to remote control of measured parameters via wireless systems, especially in remote area where access is often costly and difficult, particularly in cold seasons when, as demonstrated in this study, a higher amount of measurements is needed to ensure data of good quality. Recent achievements obtained in the framework of EU funded projects such as SMART4ACTION showed that saving on maintenance costs of the stations and keeping a high level of accuracy in the measured values is possible.
Acknowledgements
The study was funded by the SMART4Action LIFE+ project “Sustainable Monitoring And Reporting To Inform Forest and Environmental Awareness and Protection” LIFE13 ENV/IT/000813.
References
CrossRef | Gscholar
Gscholar
CrossRef | Gscholar
CrossRef | Gscholar
Authors’ Info
Authors’ Affiliation
Maurizio Marchi
Silvano Fares
CREA - Research Centre for Forestry and Wood, v.le S. Margherita 80, I-52100 Arezzo (Italy)
CREA - Research Centre for Agriculture and Environment, v. della Navicella 2-4, I-00184 Rome (Italy)
Corresponding author
Paper Info
Citation
Ferrara C, Marchi M, Fares S, Salvati L (2017). Sampling strategies for high quality time-series of climatic variables in forest resource assessment. iForest 10: 739-745. - doi: 10.3832/ifor2427-010
Academic Editor
Marco Borghetti
Paper history
Received: Mar 13, 2017
Accepted: Jun 27, 2017
First online: Aug 01, 2017
Publication Date: Aug 31, 2017
Publication Time: 1.17 months
Copyright Information
© SISEF - The Italian Society of Silviculture and Forest Ecology 2017
Open Access
This article is distributed under the terms of the Creative Commons Attribution-Non Commercial 4.0 International (https://creativecommons.org/licenses/by-nc/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.

Web Metrics
Breakdown by View Type
Article Usage
Total Article Views: 51383
(from publication date up to now)
Breakdown by View Type
HTML Page Views: 43443
Abstract Page Views: 3590
PDF Downloads: 3290
Citation/Reference Downloads: 23
XML Downloads: 1037
Web Metrics
Days since publication: 3260
Overall contacts: 51383
Avg. contacts per week: 110.33
Article Citations
Article citations are based on data periodically collected from the Clarivate Web of Science web site
(last update: Mar 2025)
Total number of cites (since 2017): 8
Average cites per year: 0.89
Publication Metrics
by Dimensions ©
Articles citing this article
List of the papers citing this article based on CrossRef Cited-by.
Related Contents
iForest Similar Articles
Editorials
COST Action FP0903: “Research, monitoring and modelling in the study of climate change and air pollution impacts on forest ecosystems”
vol. 4, pp. 160-161 (online: 11 August 2011)
Research Articles
An assessment of climate change impacts on the tropical forests of Central America using the Holdridge Life Zone (HLZ) land classification system
vol. 6, pp. 183-189 (online: 08 May 2013)
Review Papers
Increasing resistance and resilience of forests, a case study of Great Britain
vol. 17, pp. 69-79 (online: 21 March 2024)
Research Articles
Approaches to classifying and restoring degraded tropical forests for the anticipated REDD+ climate change mitigation mechanism
vol. 4, pp. 1-6 (online: 27 January 2011)
Research Articles
Potential impacts of regional climate change on site productivity of Larix olgensis plantations in northeast China
vol. 8, pp. 642-651 (online: 02 March 2015)
Research Articles
Seeing, believing, acting: climate change attitudes and adaptation of Hungarian forest managers
vol. 15, pp. 509-518 (online: 14 December 2022)
Review Papers
Impacts of climate change on the establishment, distribution, growth and mortality of Swiss stone pine (Pinus cembra L.)
vol. 3, pp. 82-85 (online: 15 July 2010)
Research Articles
Hearing nature’s heartbeat: towards large-scale real-time forest monitoring network in Italy
vol. 18, pp. 202-211 (online: 09 August 2025)
Research Articles
Forest growth and climate change: evidences from the ICP-Forests intensive monitoring in Italy
vol. 4, pp. 262-267 (online: 13 December 2011)
Commentaries & Perspectives
Availability, accessibility, quality and comparability of monitoring data for European forests for use in air pollution and climate change science
vol. 4, pp. 162-166 (online: 11 August 2011)
iForest Database Search
Search By Author
Search By Keyword
Google Scholar Search
Citing Articles
Search By Author
Search By Keywords
PubMed Search
Search By Author
Search By Keyword







